Profiler tag rules in Compute Cluster enabled environments
You can use preconfigured tag rules or create new rules based on regular expressions and values in your data to be profiled by the Data Compliance. When a tag rule is matching your data, the selected Apache Atlas classification (also known as a Cloudera Data Catalog tag) is applied.
Tag rule types
- System Defined: These are built-in rules that cannot be edited. You can only enable or disable them for your data.
- Custom: Tag rules that you create, edit and deploy
on clusters after validation will appear under this category. Click the
 icon in the Action column to enable your custom tag
rules. You can also edit these tag rules.
icon in the Action column to enable your custom tag
rules. You can also edit these tag rules.
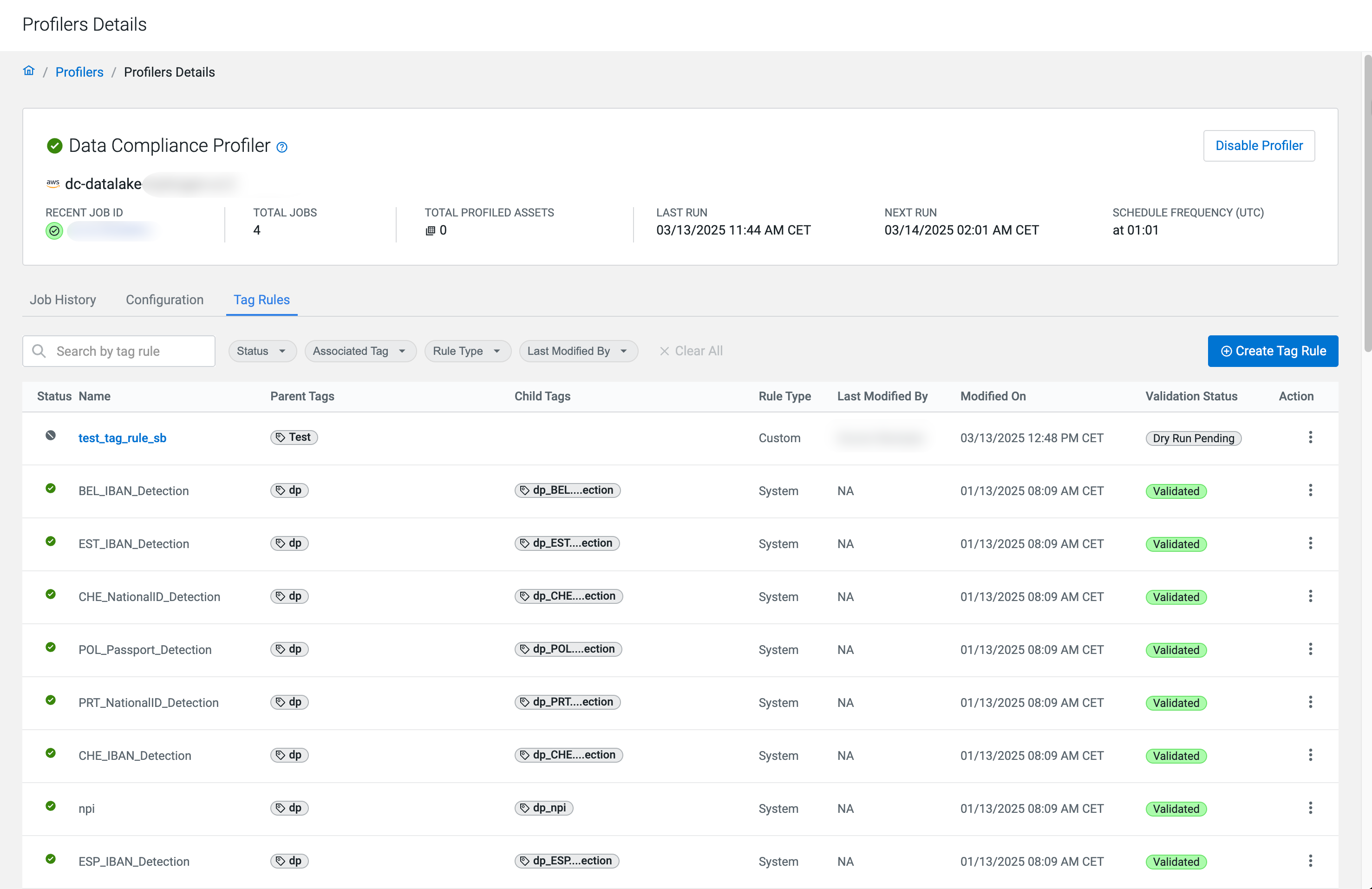
After creating your rule, you have to validate them with test data by completing a Dry Run and, only then you can click Enable.
Tag rule inputs
Tag Rules can be applied based on the following inputs:
| Input type | VM based environments | Compute Cluster enabled environments |
|---|---|---|
| Column name value | Manually entered regex pattern |
|
| Column value | Manually entered regex pattern |
|
| Table name |
|
Match thresholds and weightage
In Compute Cluster enable environments, you can adjust the Column Value Weightage for tag rules defined with regex patterns. The column value weightage percentage complements the column name weightage to 100%. This means that if you set the column value weightage to 80%, the column name adds to the final match score either 20 or zero, The reason for this is that column name matching can have only binary results (match or no match), while column value match is the number of matching values (rows) from all values in the column.
The System Deployed rules have a preset match threshold: A matching column name means a 15% confidence value. This is increased by 85% by a matching column value.
Tag rule testing
After creating your tag rule, you have to test it:
By Compute Cluster enabled environments, review them with data uploaded in a file, then save them to reach the Dry Run Pending status. Tag rules in this status must be also tested with a Dry Run on a subset of your data (up to 10 tables) in the data lake before deploying them. A Dry Run is a special on-demand profiling job.
Tag handling by tag rules
Successfully tested and enabled tag rules apply Atlas classifications or synchronized Cloudera Data Catalog tags to tables, columns.
In Compute cluster enabled environments, the parent-child tag relationships are respected. When the column value matches a child tag, the table receives the parent tag.