Behavior changes in Cloudera Data Warehouse on premises 1.5.5 SP1
Summary: Changes to Unified Analytics availability in Cloudera Data Warehouse on premise
Before this release: When creating a new Impala Virtual Warehouse, you could select the Enable Unified Analytics option.
After this release: The Enable Unified Analytics option is no longer available when creating a new Impala Virtual Warehouse. However, you can continue to create and manage Impala Unified Analytics virtual warehouses using the Cloudera CLI.
Summary: Enhanced log router resource allocation in Cloudera Data Warehouse on premise
Before this release: The resource quota of the log router component was fixed and static, failing to scale automatically with the cluster size. As clusters grew with additional nodes, the allocated quota became insufficient for the log router, which operates as a DaemonSet across all nodes. This resource deficit often caused the log router pods to remain in a Pending state and required manual quota adjustments to address the issue.
After this release: The resource quota calculation for the log router component is now improved. Cloudera Data Warehouse on premises now dynamically calculates and requests the appropriate quota by multiplying the resource request of a single log router pod by the current number of nodes it operates on. This ensures the log router consistently receives sufficient resources, eliminating the need for manual adjustments as the cluster scales.
Summary: Automatic synchronization of group name conversion between Cloudera Base on premises Ranger and Cloudera Data Warehouse
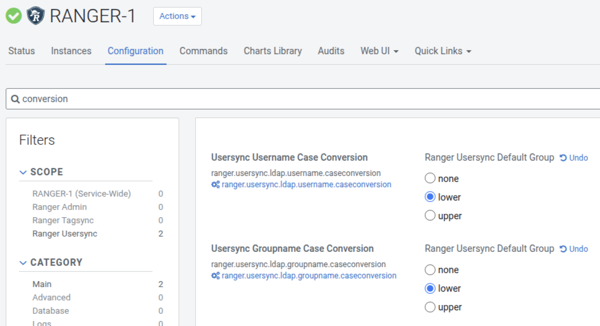
While this configuration worked correctly in Cloudera Base on premises, authorization issues could arise in Cloudera Data Warehouse components like Hive and Impala. Cloudera Data Warehouse did not automatically convert group names to lowercase, causing mismatches with Ranger policies that define group names in lowercase. This resulted in authorization problems, such as users being unable to access databases, tables, or columns in Hue or remote client shells, such as impala-shell or jdbc, even though access worked correctly in Cloudera Base on premises Hue or remote client shells.
To resolve this issue, a manual workaround was required to enable group name conversion to lowercase in Cloudera Data Warehouse. This involved adding specific Hadoop core-site configuration entries to the hadoop-core-site-default-warehouse configuration file. For Hive Virtual Warehouse, changes were applied to HiveServer2 and for Impala Virtual Warehouse, changes were applied to Impala Catalogd, Impala Coordinator, Impala Executor, and Impala StateStored.
| Property Name | Value |
|---|---|
hadoop.security.group.mapping |
org.apache.hadoop.security.RuleBasedLdapGroupsMapping |
hadoop.security.group.mapping.ldap.conversion.rule |
to_lower |
After this release: The Cloudera Data Services on premises 1.5.5 SP1 release introduces automatic synchronization of group name conversion settings between Cloudera Base on premises and Cloudera Data Warehouse. This ensures consistent handling of group names across environments.
Behavior remains unchanged if the manual Cloudera Data Warehouse workaround was previously applied, or if the Cloudera Base on premises Ranger Usersync was set to the default of none, meaning no case conversion.
Summary: Support load-based routing in impala-proxy
Before this release: impala-proxy used a
random selection policy to choose a coordinator to which to forward new OpenSession
requests.
After this release: impala-proxy now uses
load-based routing to distribute OpenSession requests across multiple active
coordinators.
Summary: Cleanup subdirectories in truncate/insert overwrite if recursing listing is enabled
Before this release: Impala did not consistently delete
files located in subdirectories of external tables during TRUNCATE and
INSERT OVERWRITE operations, even when recursive listing was enabled.
This led to leftover data in subdirectories after these operations, resulting in data
corruption.
After this release:After this change, directories are also
deleted in addition to (non-hidden) data files, with the exception of hidden and ignored
directories. Now, setting DELETE_STATS_IN_TRUNCATE=false is no longer
supported by default when truncating non-transactional tables; attempting this will result
in an exception. If the old behavior is absolutely required, you can set the
--truncate_external_tables_with_hms flag to false, but be aware that this
will also reintroduce the bug that was fixed by this change.
Apache Impala: IMPALA-14189 IMPALA-14224