Known issues for Cloudera AI on premises 1.5.5
This section lists known issues that you might run into while using Cloudera AI on premises.
- DSE-44901: Possible occurrence for incorrect status for successful workloads
-
A potential race condition in the reconciler can result in the status of successful workloads being incorrectly updated to
unknownorfailedstatus.The issue occurs due to high system load, which leads to incorrect status reporting after pod deletion.
- DSE-44699: Provisioning workbench is failing with error pool guaranteed resources larger than parent's available guaranteed resources
-
With the Quota Management feature enabled, creating Cloudera AI Workbench might fail with the error pool guaranteed resources larger than parent's available guaranteed resources.
- DSE-44367: Buildkitd Pod CrashLoopBackOff due to port conflicts
-
During the creation or upgrade of a Cloudera AI Workbench,
buildkitdpods may occasionally enter aCrashLoopBackOffstate. This typically happens when the port used by BuildKit is not properly released during pod restarts or is occupied by another process. You may encounter errors such as:buildkitd: listen tcp 0.0.0.0:1234: bind: address already in useWorkaround:
If you experience this issue, follow this step to resolve it:- Perform a rollout restart of the
buildkitdpods to ensure they start correctly:kubectl rollout restart daemonset buildkitd -n [***WORKBENCH NAMESPACE***]
- Perform a rollout restart of the
- DSE-44319 The model import from Model Hub is failing with error to communicate with Cloudera AI Registry
-
If you have used self-signed certificates or your trust store lacks the certificate required to trust the Cloudera AI Registry domain, the Cloudera AI Registry calls from the UI might fail.
Figure 1. Importing a model fails 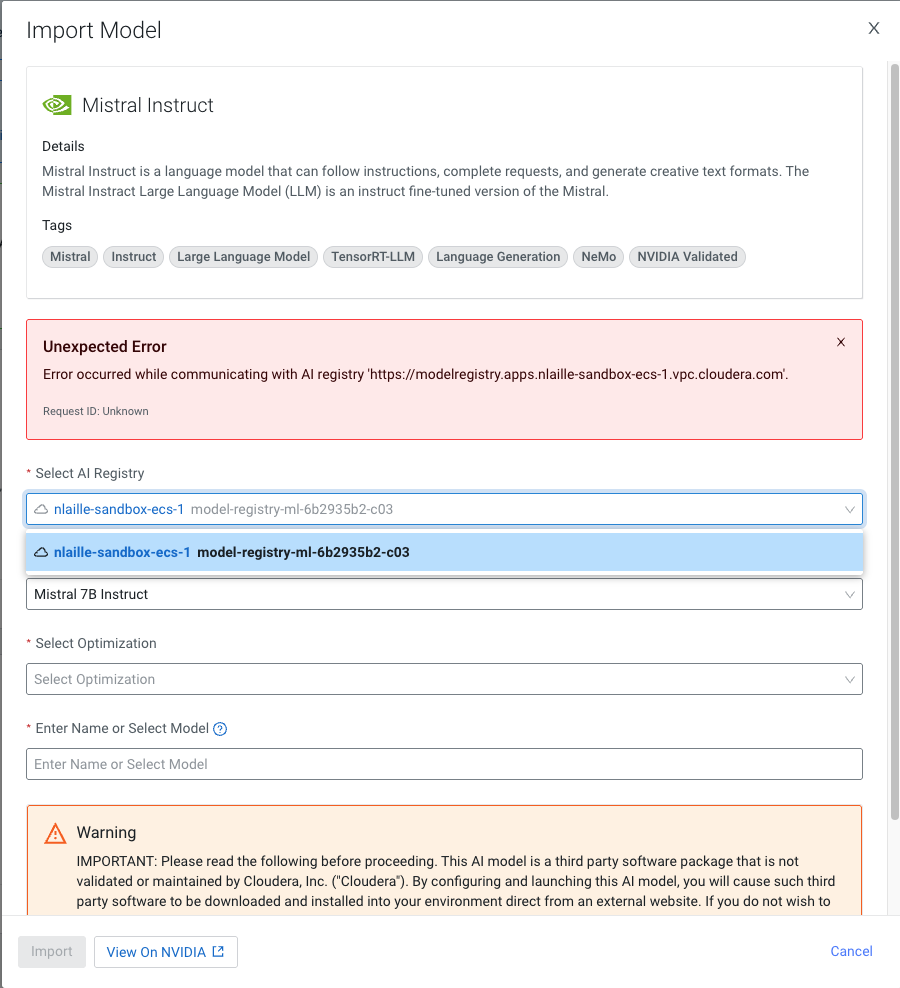
Workaround:
When facing issues with an untrusted certificate:- Select Cloudera AI Registry from the left navigation pane. The Cloudera AI Registry page is displayed.
- Open up the Cloudera AI Registry Details page.
- Copy the domain and open it in a new browser.
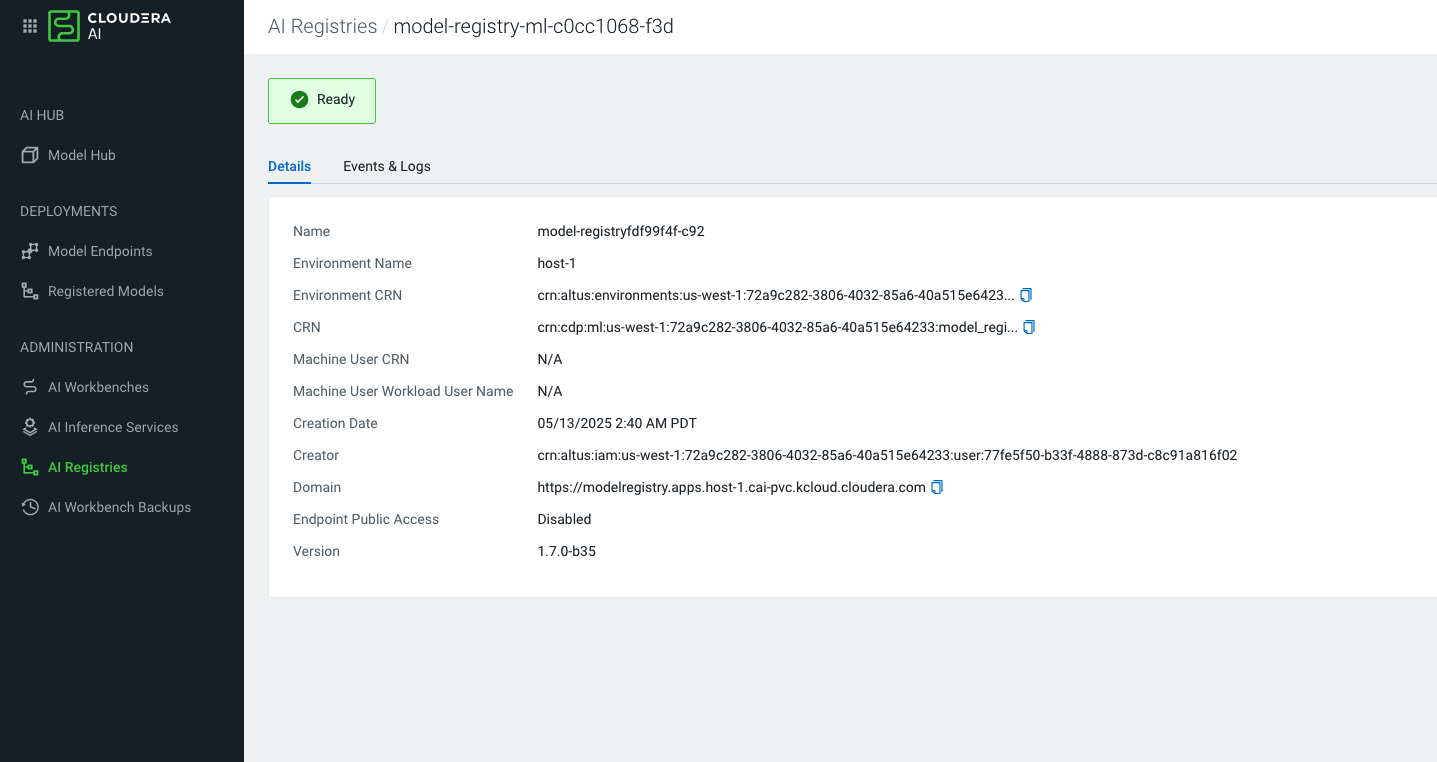
- Add the certificate permanently to your device's trust store to avoid the risk with the current session.
For permanent trust, export the certificate from your browser and import it into your operating system's certificate manager.
- DSE-43704: Rename custom tee binary to cml-tee
-
Certain vulnerability scanners may incorrectly flag Cloudera AI as using a vulnerable version of
coreutilsandtee.Cloudera AI services include a custom
teebinary, developed entirely in-house by Cloudera, which is not based on the open-sourcecoreutilslibrary. The current version of Cloudera's customteecommand is 0.9, which may be mistakenly identified as theteecommand fromcoreutilsthat contains known vulnerabilities. - DSE-44827: The model is failing with unknown status
-
Model deployments may fail to start if the model build relies on an add-on that was hotfixed in the release. This issue occurs when the model deployment restarts and the add-on hotfixing process overlap, leading to conflicts.
Workaround:
To resolve this issue, create a new build and deploy it for the affected model deployments.
- DSE-44682: Model deployment is failing at building stage due to TLS issues
-
TLS-related issues may occasionally occur during the Cloudera AI model build process in Cloudera Embedded Container Service clusters, specifically when pulling images from the container registry. These issues are typically caused by missing registry certificates on the worker nodes, which should be located at the following path:
/etc/docker/certs.d/.Workaround:
To address this issue, ensure that the required registry certificates are present on all worker nodes. Follow these steps to recover:
-
Identify a reference worker node.
Select a worker node where the model build process completes successfully without TLS errors. This node is expected to have the correct registry certificates in place. In general, any worker node running
s2i-builderpods is likely to have the necessary certificates on the nodes of the cluster. -
Locate the registry certificates.
On the reference worker node, navigate to /etc/docker/certs.d/[***REGISTRY NAME***]/ and verify that the
registry.crtfile exists. -
Distribute certificates to affected nodes.
Copy the certificate files (
registry.crt) from the reference node to the same path (/etc/docker/certs.d/[***REGISTRY NAME***]/) on the affected worker nodes that lack the required certificates. Make sure that the certificates for both the image pull and push registries are present and are correctly placed on all worker nodes. -
Perform rollout restart of the
buildkitddaemonset so that the certificates are applied properly to the buildkit pods.
-
- DSE-44913: Spark executor
fluentd initcontainer fails -
A bug introduced in a recent change to handle dynamic volume association with Spark pods causes the
Fluentbitexecutor, responsible for log collection, to crash. As a result, logs from affected pods are not included in debug bundles, and the Spark executor pod logs will not appear in the session's Logs tab in the UI.Despite this, the Spark executors will continue to function as expected—the engine container will still start, and the script will execute.
- DSE-45572: Cloudera AI Registry failure after upgrading from Cloudera 1.5.4 to 1.5.5
-
After upgrading Cloudera from version 1.5.4 to 1.5.5, you may find that the Cloudera AI Registry does not appear on the List AI Registries page. This issue occurs if you had an active Cloudera AI Registry prior to the upgrade.
Workaround:
To fix the issue and restore the visibility of Cloudera AI Registry, update the tenant field in the Cloudera database:
# exec into Cloudera database using kubectl $kubectl exec -it cdp-embedded-db-0 -n <cdp namespace> -- bash $ psql psql (10.23) Type "help" for help. postgres=# \c db-mlx update model_registry set tenant = SPLIT_PART(environment_crn,':', 5) where tenant = ''; - DSE-6499: Using dollar character in environment variables in Cloudera AI
Environment variables with the dollar ($) character are not parsed correctly by Cloudera AI. For example, if you set
PASSWORD="pass$123"in the project environment variables, and then try to read it using the echo command, the following output will be displayed:pass23Workaround: Use one of the following commands to print the $ sign:echo 24 | xxd -r -p or echo JAo= | base64 -dInsert the value of the environment variable by wrapping it in the command substitution using $() or ``. For example, if you want to set the environment variable toABC$123, specify:ABC$(echo 24 | xxd -r -p)123 or ABC`echo 24 | xxd -r -p`123- DSE-40198: Resolve painpoints with installations and updates of self-signed certificates
-
When rotating or updating the TLS certificate used by Cloudera AI, the Cloudera AI does not automatically pull the new certificate from the Cloudera Control Pane. To update Cloudera AI with a new TLS certificate, follow the steps below.
Workaround:
-
Backup the existing ConfigMap.
Create a backup of the currentprivate-cloud-ca-certs-pem-2ConfigMap in your existing Cloudera AI Workbench using the following command:kubectl get configmap private-cloud-ca-certs-pem-2 -n [***existing CAI workbench namespace***] -o yaml > private-cloud-ca-certs-pem-2.backup -
Create a temporary TLS-enabled workbench.
Spin up a new, temporary TLS-enabled workbench in the same cluster and environment as the existing workbench. (It is not necessary for the workbench to start up correctly. You do not need to allocate a full set of resources for this cluster.)
-
Locate the ConfigMap in the new workbench.
Once the Cloudera AI infrastructure pods in the new workbench are running, retrieve theprivate-cloud-ca-certs-pem-2ConfigMap using this command:kubectl get configmap private-cloud-ca-certs-pem-2 -n [***new CAI workbench namespace***] -o yaml -
Update the existing workbench with the new certificate.
Replace thebinaryData: cacertsvalue in the existing ConfigMap of the Cloudera AI Workbench with thebinaryData: cacertsvalue from the new workbench. The simplest way to perform this replacement is through the Cloudera Embedded Container Service UI. This data is a large base64-encoded string. To verify the new TLS certificate, decode the string and inspect its content using the OpenSSL tool:kubectl get configmap private-cloud-ca-certs-pem-2 -n [***new CAI workbench namespace***] -o yaml | grep cacerts | awk '{print $2}' | base64 -d > decoded-private-cloud-ca-certs-pem.pem while openssl x509 -noout -text; do :; done < decoded-private-cloud-ca-certs-pem.pem - Restart pods in the existing workbench. Restart the
ds-cdhpod in the old namespace. Additionally, restart any other pods in the old namespace that fail to come up automatically. - Delete the temporary workbench. After confirming that the old Cloudera AI Workbench is functioning correctly with the updated certificate, delete the temporary workbench.
By following these steps, you can successfully update the TLS certificate for Cloudera AI while ensuring minimal disruption to your existing workbench.
-
- DSE-12064: Terminal remains functional after web session times out
- The Cloudera AIterminal remains active even after the Cloudera AI web session has timed out.
- DSE-44698: Restart Stabilty - Cloudera AI Workbench pod preemption by system-critical workloads
-
During control plane upgrades or cluster restarts, Cloudera AI Workbench pods may transition into the
Init:ErrororInit:ContainerStatusUnknownstate.This issue may arise during cluster startup or under resource pressure when the scheduler preempts lower-priority Cloudera AI Workbench pods to allocate resources for higher-priority system pods, such as critical system components. Additionally, Kubernetes does not automatically clean up preempted pods, leaving them in failed
Initstates.This is the expected Kubernetes scheduler behavior. There is no permanent fix available, as pod preemption is controlled by the Kubernetes scheduler and is necessary for system stability during resource constraints.
Workaround:
Delete the affected pod, and Kubernetes automatically attempts to reschedule it if sufficient resources are available:kubectl delete pod [***POD NAME***] -n [***CLOUDERA AI WORKBENCH NAMESPACE***]
Cloudera AI Inference service Known issues
- DSE-44238: Cannot create Cloudera AI Inference service application deployment via CDP CLI when ozone credentials are passed
-
Cloudera AI Inference service cannot be created via CDP CLI. Create the Cloudera AI Inference service only via the UI.
- DSE-44141: Failed to delete deployment in executing DeleteMLServingApp
-
Cloudera AI Inference service fails to remove all namespaces if the Cloudera AI Inference service is deleted post installation failure.
Workaround:
Manually delete the below namespaces from the cluster:- knative-serving
- kserve
- cml-serving
- knox-caii
- serving-default
- DSE-46352: Kserve fails to pull images in airgapped environments where the docker registry is not listed in the trusted list
-
In airgapped environments, model endpoints fail with an error message due to the Docker registry not being included in the trusted list. The trusted list is defined in the
registries-skipping-tag-resolvingconfiguration, which is part of theconfig-deploymentconfiguration map located in theknative-servingnamespace.
Further known issues with Cloudera AI Inference service:
- Updating the description after a model has been added to a model endpoint will lead to a UI mismatch in the model builder for models listed by the model builder and the models deployed.
- Embedding models function in two modes:
queryorpassage. This has to be specified when interacting with the models. There are two ways to do this:-
suffix the model id in the payload by either
-queryor-passageor -
specify the
input_typeparameter in the request payload.For more information, see NVIDIA documentation.
-
-
Embedding models only accept strings as input. Token stream input is currently not supported.
-
Llama 3.2 Vision models are not supported on AWS on A10G and L40S GPUs.
-
Llama 3.1 70B Instruct model L40S profile needs 8 GPUs to deploy successfully, while NVIDIA documentation lists this model profile as needing only 4 L40S GPUs.
- Mistral 7B models for NIM version 1.1.2 require the max_tokens parameter in the request payload. This API regression is known to affect the Test Model UI functionality for this specific NIM version.
- NIM endpoints will reply with a 307 temporary redirect if the URL ends with a trailing /. Make sure not to have a trailing slash character at the end of NIM endpoint URLs.