Cloudera Navigator Metadata Architecture
Cloudera Navigator metadata supports data discovery and data lineage functions. The following figure depicts the Cloudera Navigator metadata architecture.
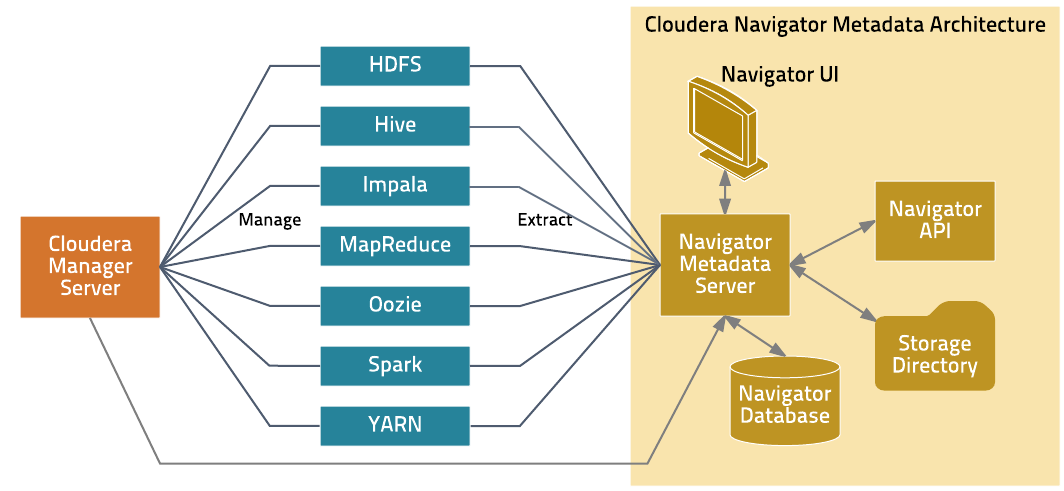
- Obtains connection information about CDH services from the Cloudera Manager Server
- Extracts metadata periodically for the entities managed by those services
- Manages and applies metadata extraction policies during metadata extraction
- Indexes and stores entity metadata
- Manages authorization data for Cloudera Navigator users
- Manages audit report metadata
- Generates metadata and audit analytics
- Exposes the Cloudera Navigator APIs
- Hosts the web server that provides the Cloudera Navigator console
The Navigator database stores policies, user authorization and audit report metadata, and analytic data. Extracted metadata and the state of extractor processes is kept in the storage directory.
Three Different Classes of Metadata
The Cloudera Navigator Metadata Server manages metadata about the entities in a CDH cluster and relations between the entities. Any given entity can be identified by one or more of the three different classes of metadata listed in the table:
| Category | Description | Usage Note |
|---|---|---|
| Technical Metadata | Characteristics inherent to the entity that are obtained when extracted. | Not modifiable. |
| Managed Metadata | Descriptions, tags, and key-value pairs that can be added to entities after extraction. Keys are defined within namespaces, and values can be constrained by type (Text, Number, Boolean, Date, Enumeration, for example). | Add to entities or modify after extraction only. |
| Custom Metadata | Key-value pairs that can be added to entities before or after extraction. Displayed in the Tags area of the Details page for a given entity. | Add to entities before or after extraction. |
For example, the screenshot below shows the details of a web log saved to HDFS as a comma-separated value (CSV) file. This particular entity has all three types of metadata associated with it. Its Technical Metadata is applied by the source system, in this case, HDFS. The self-service data discovery aspect of this file—the ability for business users to find it—has been augmented thanks to the addition of the Finance department metadata (from the Classification namespace), shown in the Managed Metadata section of the file details. Finally, the Tags area of file details shows that Custom Metadata has also been applied to this file.
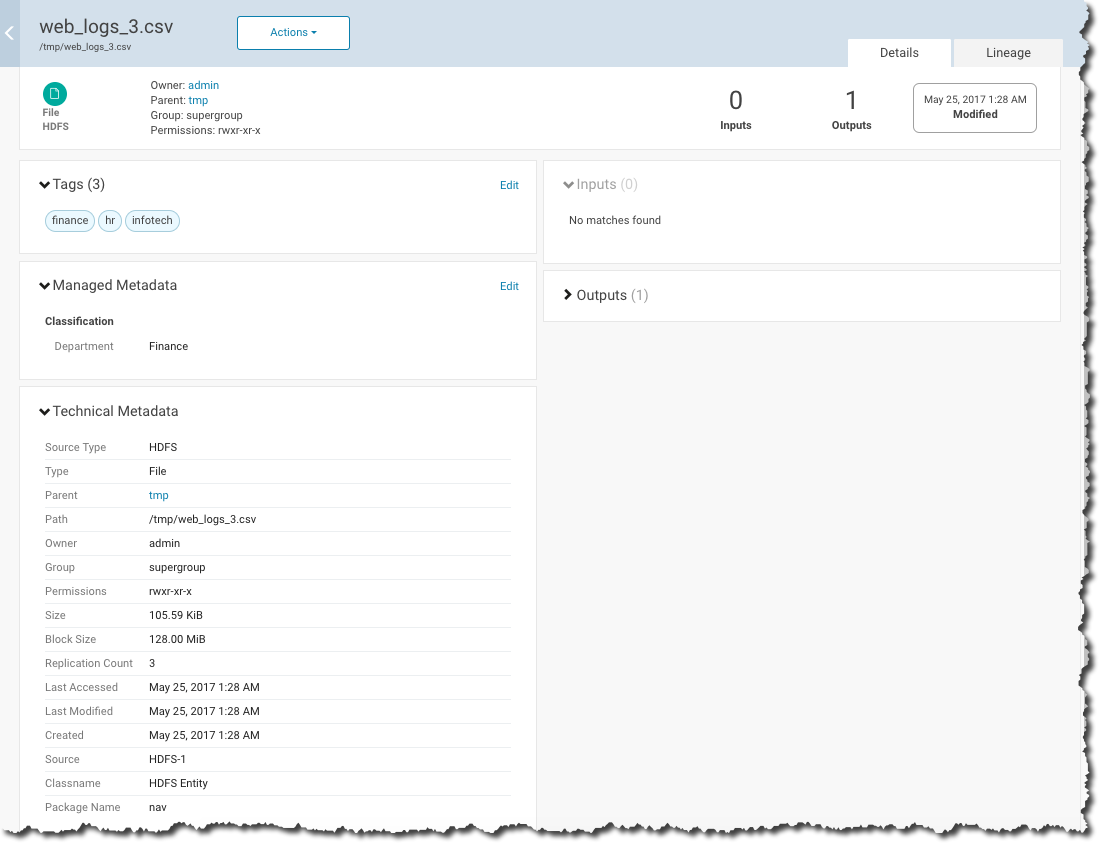
The Technical Metadata is obtained from the source entity and cannot be modified. Common examples of Technical Metadata include an entity's name, type (directory or file, for example), path, creation date and time, and access permissions. For entities created or managed by cluster services, Technical Metadata may include the name of the service that manages or uses that entity and relations—parent-child, data flow, and instance of—between entities.
As another example, Technical Metadata for an Amazon S3 bucket includes Bucket name, Region (AWS Region, such as us-west-1), S3 Encryption, S3 Storage Class, S3 Etag, Source (S3), and so on. In short, Technical Metadata is simply whatever metadata is provided for the entity by the system that created the entity. For example, for Hive entities, Cloudera Navigator extracts the extended attributes added by Hive clients to the entity.