Running Spark Applications on YARN
When Spark applications run on a YARN cluster manager, resource management, scheduling, and security are controlled by YARN.
Continue reading:
- Deployment Modes
- Configuring the Environment
- Running a Spark Shell Application on YARN
- Submitting Spark Applications to YARN
- Monitoring and Debugging Spark Applications
- Example: Running SparkPi on YARN
- Configuring Spark on YARN Applications
- Dynamic Allocation
- Optimizing YARN Mode in Unmanaged CDH Deployments
Deployment Modes
In YARN, each application instance has an ApplicationMaster process, which is the first container started for that application. The application is responsible for requesting resources from the ResourceManager. Once the resources are allocated, the application instructs NodeManagers to start containers on its behalf. ApplicationMasters eliminate the need for an active client: the process starting the application can terminate, and coordination continues from a process managed by YARN running on the cluster.
For the option to specify the deployment mode, see spark-submit Options.
Cluster Deployment Mode
In cluster mode, the Spark driver runs in the ApplicationMaster on a cluster host. A single process in a YARN container is responsible for both driving the application and requesting
resources from YARN. The client that launches the application does not need to run for the lifetime of the application.
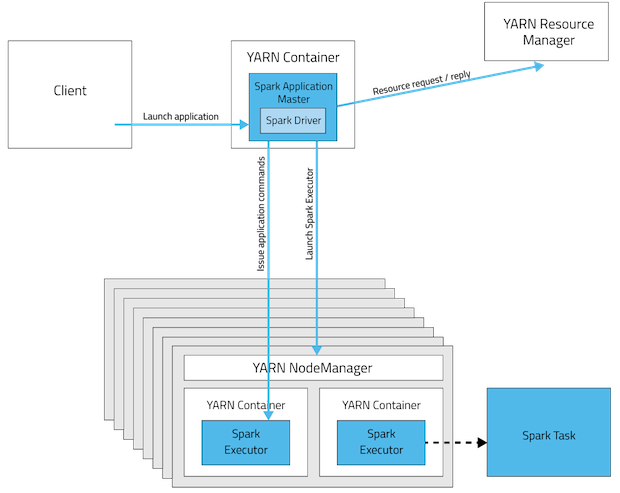
Cluster mode is not well suited to using Spark interactively. Spark applications that require user input, such as spark-shell and pyspark, require the Spark driver to run inside the client process that initiates the Spark application.
Client Deployment Mode
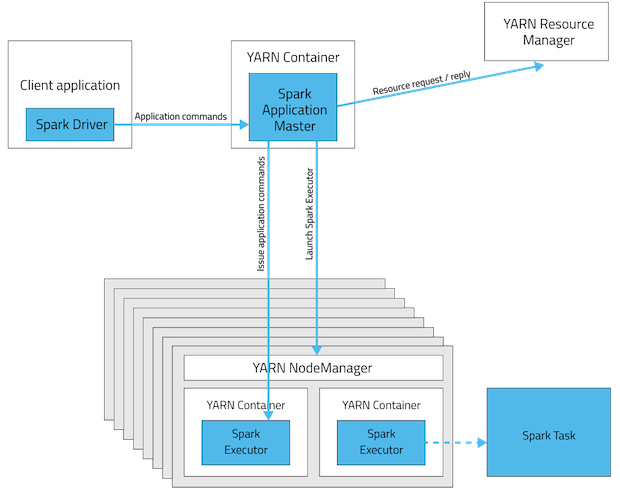
In client mode, the Spark driver runs on the host where the job is submitted. The ApplicationMaster is responsible only for requesting executor containers from YARN. After the containers
start, the client communicates with the containers to schedule work.
| Mode | YARN Client Mode | YARN Cluster Mode |
|---|---|---|
| Driver runs in | Client | ApplicationMaster |
| Requests resources | ApplicationMaster | ApplicationMaster |
| Starts executor processes | YARN NodeManager | YARN NodeManager |
| Persistent services | YARN ResourceManager and NodeManagers | YARN ResourceManager and NodeManagers |
| Supports Spark Shell | Yes | No |
Configuring the Environment
Spark requires that the HADOOP_CONF_DIR or YARN_CONF_DIR environment variable point to the directory containing the client-side configuration files for the cluster. These configurations are used to write to HDFS and connect to the YARN ResourceManager. If you are using a Cloudera Manager deployment, these variables are configured automatically. If you are using an unmanaged deployment, ensure that you set the variables as described in Running Spark on YARN.
Running a Spark Shell Application on YARN
To run the spark-shell or pyspark client on YARN, use the --master yarn --deploy-mode client flags when you start the application.
If you are using a Cloudera Manager deployment, these properties are configured automatically.
Submitting Spark Applications to YARN
To submit an application to YARN, use the spark-submit script and specify the --master yarn flag. For other spark-submit options, see spark-submit Arguments.
Monitoring and Debugging Spark Applications
To obtain information about Spark application behavior you can consult YARN logs and the Spark web application UI. These two methods provide complementary information. For information how to view logs created by Spark applications and the Spark web application UI, see Monitoring Spark Applications.
Example: Running SparkPi on YARN
These examples demonstrate how to use spark-submit to submit the SparkPi Spark example application with various options. In the examples, the argument passed after the JAR controls how close to pi the approximation should be.
In a CDH deployment, SPARK_HOME defaults to /usr/lib/spark in package installations and /opt/cloudera/parcels/CDH/lib/spark in parcel installations. In a Cloudera Manager deployment, the shells are also available from /usr/bin.
Running SparkPi in YARN Cluster Mode
- CDH 5.2 and lower
spark-submit --class org.apache.spark.examples.SparkPi --master yarn \ --deploy-mode cluster SPARK_HOME/examples/lib/spark-examples.jar 10
- CDH 5.3 and higher
spark-submit --class org.apache.spark.examples.SparkPi --master yarn \ --deploy-mode cluster SPARK_HOME/lib/spark-examples.jar 10
The command prints status until the job finishes or you press control-C. Terminating the spark-submit process in cluster mode does not terminate the Spark application as it does in client mode. To monitor the status of the running application, run yarn application -list.
Running SparkPi in YARN Client Mode
- CDH 5.2 and lower
spark-submit --class org.apache.spark.examples.SparkPi --master yarn \ --deploy-mode client SPARK_HOME/examples/lib/spark-examples.jar 10
- CDH 5.3 and higher
spark-submit --class org.apache.spark.examples.SparkPi --master yarn \ --deploy-mode client SPARK_HOME/lib/spark-examples.jar 10
Configuring Spark on YARN Applications
In addition to spark-submit Options, options for running Spark applications on YARN are listed in spark-submit on YARN Options.
| Option | Description |
|---|---|
| archives | Comma-separated list of archives to be extracted into the working directory of each executor. For the client deployment mode, the path must point to a local file. For the cluster deployment mode, the path can be either a local file or a URL globally visible inside your cluster; see Advanced Dependency Management. |
| executor-cores | Number of processor cores to allocate on each executor. Alternatively, you can use the spark.executor.cores property. |
| executor-memory | Maximum heap size to allocate to each executor. Alternatively, you can use the spark.executor.memory property. |
| num-executors | Total number of YARN containers to allocate for this application. Alternatively, you can use the spark.executor.instances property. |
| queue | YARN queue to submit to. For more information, see Assigning Applications and Queries to Resource Pools.
Default: default. |
During initial installation, Cloudera Manager tunes properties according to your cluster environment.
In addition to the command-line options, the following properties are available:
| Property | Description |
|---|---|
| spark.yarn.driver.memoryOverhead | Amount of extra off-heap memory that can be requested from YARN per driver. Combined with spark.driver.memory, this is the total memory that YARN can use to create a JVM for a driver process. |
| spark.yarn.executor.memoryOverhead | Amount of extra off-heap memory that can be requested from YARN, per executor process. Combined with spark.executor.memory, this is the total memory YARN can use to create a JVM for an executor process. |
Dynamic Allocation
Dynamic allocation allows Spark to dynamically scale the cluster resources allocated to your application based on the workload. When dynamic allocation is enabled and a Spark application has a backlog of pending tasks, it can request executors. When the application becomes idle, its executors are released and can be acquired by other applications.
Starting with CDH 5.5, dynamic allocation is enabled by default. Dynamic Allocation Properties describes properties to control dynamic allocation.
If you set spark.dynamicAllocation.enabled to false or use the --num-executors command-line argument or set the spark.executor.instances property when running a Spark application, dynamic allocation is disabled. For more information on how dynamic allocation works, see resource allocation policy.
When Spark dynamic resource allocation is enabled, all resources are allocated to the first submitted job available causing subsequent applications to be queued up. To allow applications to acquire resources in parallel, allocate resources to pools and run the applications in those pools and enable applications running in pools to be preempted. See Dynamic Resource Pools.
If you are using Spark Streaming, see the recommendation in Spark Streaming and Dynamic Allocation.
| Property | Description |
|---|---|
| spark.dynamicAllocation.executorIdleTimeout | The length of time executor must be idle before it is removed.
Default: 60 s. |
| spark.dynamicAllocation.enabled | Whether dynamic allocation is enabled.
Default: true. |
| spark.dynamicAllocation.initialExecutors | The initial number of executors for a Spark application when dynamic allocation is enabled.
Default: 1. |
| spark.dynamicAllocation.minExecutors | The lower bound for the number of executors.
Default: 0. |
| spark.dynamicAllocation.maxExecutors | The upper bound for the number of executors.
Default: Integer.MAX_VALUE. |
| spark.dynamicAllocation.schedulerBacklogTimeout | The length of time pending tasks must be backlogged before new executors are requested.
Default: 1 s. |
Optimizing YARN Mode in Unmanaged CDH Deployments
In CDH deployments not managed by Cloudera Manager, Spark copies the Spark assembly JAR file to HDFS each time you run spark-submit. You can avoid this copying by doing one of the following:
- Set spark.yarn.jar to the local path to the assembly JAR: local:/usr/lib/spark/lib/spark-assembly.jar.
- Upload the JAR and configure the JAR location:
- Manually upload the Spark assembly JAR file to HDFS:
$ hdfs dfs -mkdir -p /user/spark/share/lib $ hdfs dfs -put SPARK_HOME/assembly/lib/spark-assembly_*.jar /user/spark/share/lib/spark-assembly.jar
You must manually upload the JAR each time you upgrade Spark to a new minor CDH release. - Set spark.yarn.jar to the HDFS path:
spark.yarn.jar=hdfs://namenode:8020/user/spark/share/lib/spark-assembly.jar
- Manually upload the Spark assembly JAR file to HDFS: